同一个需求,三种做法,完全不同的结果。这篇文章分享我们终端团队从”让 AI 写代码”到”让 AI 参与工程全流程”的实践路径。
写在前面
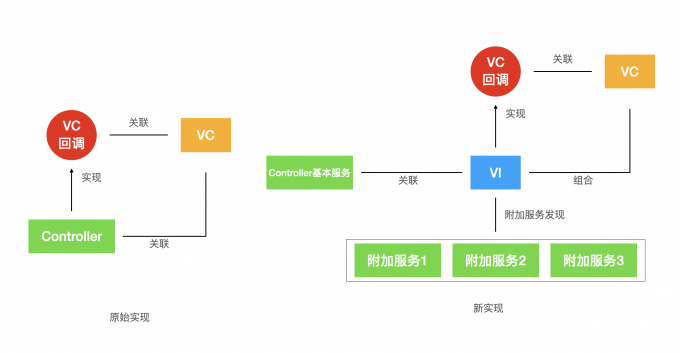
我们是一个终端团队,工作区下面挂了多个组件仓——基础层、业务层、调试工具,宿主仓负责装配。
过去一年,我们逐步把 AI 编程助手接入了开发流程。不是简单让 AI 写代码,而是从需求抓取到代码归档,每个环节都有 AI 参与。
这篇文章会讲四件事:
- 三种模式有什么不同——纯人肉 / Vibe Coding / AI 全流程工程化
- 为什么 Vibe Coding 不够用——我们踩过的核心问题
- 全流程工程化具体怎么做——每个环节的工具、规则和产物
- 怎么一步步走到这里——学习路线和经验教训
一、三种模式:同一个需求,三种命运
产品在钉钉丢过来一个 PRD:「换肤配置」——用户可以为游戏选择不同的皮肤主题。需求涉及:UI 换肤逻辑、主题资源包下载、配置后台对接、异常降级。跨了宿主仓和业务组件仓。
同样的需求,三种模式下会发生什么?
模式定义
| 模式 | 一句话 | AI 的角色 |
|---|---|---|
| 纯人肉 | 从头到尾自己干 | 没有 AI |
| Vibe Coding | 让 AI 写代码,我指挥 | 打字员,你说它写 |
| AI 全流程工程化 | AI 参与每个环节,受规则约束 | 全流程协作者,有边界有规矩 |
逐环节对比
1. 需求获取
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| PRD 获取 | 手动阅读,脑子记 | 复制文字粘贴给 AI | 自动截图抓取,AI 可读 |
| API 获取 | 手动抄字段 | 复制粘贴 | 自动抓取,结构化 JSON |
| 原型图 | 截图存本地 | AI 看不到 | 合并截图,AI 可读 |
| 信息完整度 | 依赖人的记忆力 | 只有文字,丢图 | 完整保留 |
2. 需求评审
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 谁在审 | 开发自己审 | 没人审 | AI 先审,结构化评审 |
| 什么时候发现问题 | 做到一半 | 测试阶段 | 编码之前 |
| 返工成本 | 中等 | 最高(写完重来) | 最低(提前拦截) |
3. 方案设计
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 有没有方案文档 | 在脑子里 | 没有 | 有,结构化产物 |
| AI 什么时候介入 | 不介入 | 直接写代码 | 先设计,再实现 |
| 方向偏了什么时候发现 | 写到一半 | 写完 | 动手之前 |
4. 编码实现
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 代码产出速度 | 慢 | 快 | 快 |
| 是否符合项目规范 | 靠人记 | 经常不符合 | 规则约束,首次即对 |
| 修规范问题的成本 | 无(自己写的) | 高(可能和写代码一样久) | 低(规则前置约束) |
| 净效率 | 基线 | 看起来快,实际未必 | 最高 |
5. 代码审查
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 审查覆盖面 | 看什么算什么 | 表面风格 | 领域专项 + 项目约束 |
| 能否发现性能问题 | 靠经验 | 几乎不能 | 内置检查项 |
| 结果可执行性 | 模糊 | 模糊 | 带严重级别,明确动作 |
6. 工程规范
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 分支名/Commit 规范 | 靠自觉 | AI 不知道规范 | 规则约束,自动合规 |
| 组件联调 | 手动重复操作 | AI 不会 | 一个命令自动化 |
7. 变更归档
| 纯人肉 | Vibe Coding | 全流程工程化 | |
|---|---|---|---|
| 方案文档 | 无 | 无 | 有,结构化归档 |
| 设计取舍记录 | 在脑子里/会议纪要 | 无 | design.md |
| 新人接手成本 | 高 | 高 | 低 |
同一个需求,从收到 PRD 到上线
纯人肉:5 天
Day 1 看 PRD,脑子想方案 → Day 2-3 写代码 → Day 4 做到一半发现 PRD 没写异常降级,停下来等产品 → Day 5 补完逻辑,提交 MR。没有方案文档,半年后新人问「为什么这么设计」,没人答得上来。
Vibe Coding:看起来 2 天,实际 4 天
Day 1 把 PRD 文字贴给 AI,产出很快 → Day 2 发现 AI 把代码写错了仓,用了错误的技术栈,手动改 → Day 3 测试发现异常降级没做,补代码 → Day 4 AI review 说「代码不错」,但测试提了 5 个 bug,逐个修。没有方案文档,没有需求评审记录。
AI 全流程工程化:3 天(含前期准备)
Day 1 上午抓 PRD 和 API,AI 评审发现 3 个 P0 阻塞项 → Day 1 下午拿评审报告找产品补需求,同时走变更流程:proposal → design → tasks → Day 2 按任务清单编码,AI 在规则约束下首次即对仓、对技术栈 → Day 3 AI 审查发现 1 个严重项,修完提交 MR,归档变更。3 天完成,产出不仅是一段代码,还有需求评审报告、方案文档、任务清单、代码审查记录、能力基线。
二、为什么 Vibe Coding 不够用
看到上面的对比,你可能会问:Vibe Coding 不是挺快的吗?为什么还要搞全流程工程化?
我们不是一开始就做全流程工程化的。路径是这样的:
1 | 纯人肉 → 觉得效率低 → 引入 AI → Vibe Coding → 发现问题 → 全流程工程化 |
从纯人肉到 Vibe Coding 的动力很简单:AI 写代码快,这谁都知道。但从 Vibe Coding 到全流程工程化,原因更值得说:
1. AI 写得快但改得慢
它不知道团队的规范——用哪个网络库、解析库、埋点 SDK。产出越多,修正成本越高。你花了和 AI 写代码一样长的时间,在修这些”风格不对”的问题。
2. AI 不会质疑需求
你让它做,它就做。PRD 没写异常降级?它不管。交互细节缺失?它按自己理解补。做到一半发现方向偏了,浪费更大。
3. AI 没有上下文
PRD 在钉钉,API 在 ShowDoc,设计稿在 Figma——这些都在外部系统里,AI 看不到。写出来的代码凭想象,复制粘贴又丢图丢结构。
4. AI 审查自己写的代码是无效的
让 AI review 自己写的代码,它当然觉得不错。通用 review 说”这个函数有点长”——帮助不大。真正的问题没人发现:启动链路阻塞、UI 线程卡顿、网络层不合规。
5. 没有文档的代码就是技术债
AI 写的代码尤其如此——因为没人完整理解它。半年后新人问「为什么这么设计」,git log 里只有一堆看不出意图的 commit。
全流程工程化的本质,不是给 AI 加更多限制,而是把 AI 从”打字员”升级为”带规矩的协作者”:
- 它知道该改哪个仓(归属路由)
- 它知道该用什么技术栈(规则约束)
- 它知道需求有没有漏洞(PRD 评审)
- 它知道代码有没有隐患(领域化审查)
- 它知道做完之后要留下什么(变更归档)
三、全流程工程化:具体怎么做
1. 工具选型:三把刀,但只磨一块磨刀石
团队里 Cursor、Claude Code、Kiro 都在用,不强求统一工具,但有一个原则必须统一:AI 规则只维护一份,所有工具共享。
1 | .cursor/rules/*.mdc ← 核心规则定义(唯一真实来源) |
规则写在 .cursor/rules/,这是唯一的”磨刀石”。.kiro/steering/ 是镜像给 Kiro 用的,CLAUDE.md 是分流入口告诉 Claude Code 遇到什么问题去看哪个规则。
早期各子仓自己带了 .cursorrules、.kiro/、.trae/,结果不同工具看到的规则不一致,AI 行为不可预测。后来我们专门做了一个变更把子仓的 AI 配置全部清理掉,统一收敛到工作区根目录。教训:子仓零配置,根目录统一定义。
2. 多仓架构:让 AI 知道”这事不归你管”
AI 助手最常犯的错:你让它修一个属于组件仓的 bug,它直接在宿主仓里加了个 workaround。这在多仓架构里是灾难。
我们给 AI 写了一个归属判断路由器,而不是把所有规则扁平堆在一起:
1 | 任务进来 |
AI 在动手之前会先走这个路由,判断该改哪里。越界改仓的情况大幅减少。
3. 需求阶段:把外部文档搬进 AI 的视野
我们的 PRD 写在钉钉文档,API 文档写在 ShowDoc。这些都在外部系统里,AI 看不到。
两个 Playwright 自动化技能解决了这个问题:
- dd-prd-claw:钉钉文档 → 慢滑截图 → 去重合并 → AI 可读的完整 PRD(包括原型图和标注)
- dd-api-claw:ShowDoc → 提取文本 → 结构化 JSON(同时产出纯文本和 JSON,方便不同场景消费)
抓取后的文档就在工作区里,AI 助手可以直接读取。不需要人工搬运。
4. PRD 评审:让 AI 先审需求,再写代码
开发做到一半才发现 PRD 没写清楚某个交互细节——这是最常见的返工原因。
dd-prd-judge 对抓取的 PRD 做实现前评审:
| 评审维度 | 审什么 |
|---|---|
| 用户流程 | 核心路径完整吗?分支流程覆盖了吗? |
| 交互规格 | 状态切换、动画、手势写清楚了吗? |
| 业务规则 | 计算逻辑、边界条件定义了吗? |
| 数据契约 | 字段定义、必填/选填、枚举值给了吗? |
| 异常处理 | 断网、超时、降级描述了吗? |
| 验收标准 | 有没有可执行的测试用例? |
风险分级:P0(阻塞开发,必须补)→ P1(必然返工,当前迭代补)→ P2(不阻塞,开发中补)→ P3(建议优化,后续处理)。
实际案例:「换肤配置」PRD 评审得分 58/100,标注了多个 P0 阻塞项——用户流程不完整、交互规格缺失、异常处理未覆盖。这些问题在编码前就被拦截了。
5. 变更管理:让每一步都有据可查
以前做功能,经常是”PRD 丢过来 → 直接写代码 → 写完发现方向偏了”。我们引入了 spec-driven 模式,给变更流程加上结构化中间产物:
1 | proposal.md ──→ delta spec ──→ design.md ──→ tasks.md |
| 产物 | 回答的问题 |
|---|---|
proposal.md |
为什么要做?改什么?影响范围? |
delta spec |
新增/变更了什么能力? |
design.md |
技术方案是什么?影响哪些模块? |
tasks.md |
具体要做哪些事?优先级怎么排? |
归档后,delta spec 合入 main spec。下次再改同一块能力时,AI 能看到历史基线。半年后新人接手,看归档就知道当初的设计取舍。
最大的变化是:**AI 不再直接写代码,而是先过一遍”为什么要做、怎么做、分几步”**。
6. 工程自动化:把团队规范写进 AI 的肌肉记忆
Git 工作流规范
| 规范 | 规则 | AI 行为 |
|---|---|---|
| 分支名 | feature/[任务号]-中文描述 |
AI 创建分支时自动遵循 |
| Commit | -#任务号 提交信息 |
AI 写 commit 时自动带任务号 |
| 推送保护 | 禁止推 master/develop | AI 推送前检查分支名 |
多仓组件联调
联调时切本地源码,以前要手动读 Podfile 版本 → 去组件仓 checkout 对应 tag → 写本地配置文件,多个组件仓重复操作。现在一个命令搞定,支持 --dry-run 预览。
AI 生成的 commit 和分支不再需要人工修正格式。
7. 代码审查:不是通用 review,是领域专家 review
通用 AI 代码审查会说”这个函数太长了”——帮助不大。我们关心的是:会不会影响启动速度?会不会卡 UI 线程?有没有走规定的网络层?
以下是我们在移动端的实践,思路可迁移到其他终端领域:
dd-code-review 内置了质量六维模型:
| 维度 | 典型问题(以移动端为例) | 严重级别 |
|---|---|---|
| 启动性能 | 应用启动时同步读磁盘/发请求 | [严重] |
| 流畅度 | 列表滚动时重复创建视图 | [主要] |
| 稳定性 | 强制解包服务端可选字段 | [严重] |
| 耗电 | 后台未停止的定时器 | [主要] |
| 网络 | 相同请求未复用缓存 | [次要] |
| 发布风险 | Release 包含调试入口 | [严重] |
还内置了项目级约束检查:网络请求是否走了规定的网络层?解析是否用了规定的解析库?埋点是否接了规定的监控 SDK?
审查结果带严重级别:[严重] 必须修、[主要] 应当修、[次要] 建议修、[挑刺] 可忽略。不再是泛泛的代码风格建议,而是带业务上下文的可执行行动项。
8. 全流程串起来
1 | 钉钉 PRD ──┐ ┌── 代码审查 ──→ 合入 |
一句话:需求进来 → 先抓取 → 再评审 → 然后设计拆任务 → 编码(受规则约束+工程自动化)→ 审查 → 归档。AI 参与了每一个环节。
四、学习路线:从用到工程化
前面是我们的实践结果,但团队不是一步到位的。这条路怎么走?我们总结了三个阶段:
阶段一:上手(1-2 周)—— 先用起来
目标:让 AI 参与每天的开发工作,建立基本手感
- 两个工具都要会:Cursor 擅长编辑器内实时辅助,Claude Code 擅长终端级多文件任务,从真实小任务开始
- 核心习惯:小步给指令,每步 review——不要一次性甩一个大需求
- 给项目写 Rules(Cursor 的
.cursor/rules/ Claude Code 的CLAUDE.md),让 AI 懂你的项目约定 - 关键体感:Rules 越具体,AI 输出越稳定
自测验证:
| 验证项 | 达标线 |
|---|---|
| 两个工具都能用 | Cursor 能独立完成行内编辑 + 上下文引用;Claude Code 能产出可直接 review 的 PR |
| 工具选择合理 | 回顾最近 5 次任务,至少 3 次选择合理(编辑器内小改用 Cursor,跨文件/终端任务用 Claude Code) |
| Rules 生效 | 有 Rules 时 AI 输出明显更贴合项目约定 |
阶段二:提效(2-4 周)—— 改变工作方式
目标:从”AI 写代码”升级为”你写 Spec,AI 实现”
最核心的方法论是 Spec 编程:
1 | 需求 → 写 Spec → AI 出方案 → 你确认 → AI 写代码 → 你审查 |
Spec 越清楚,AI 输出越靠谱;模糊输入 = 随机输出。
Prompt 质量是 Spec 编程的基础:
- 好的 Prompt = 清晰目标 + 充分上下文 + 明确约束
- 太模糊或太详细都不行,给方向和边界,让 AI 决定实现
- 常见反例:
- “优化一下这个函数” → AI 不知道优化性能?可读性?兼容性?
- “帮我写个登录页” → 缺少技术栈、设计规范、接口约定,输出不可控
- “按照第一行到第三行的方式,写第四行” → 逐行指挥,不如描述整体模式让 AI 批量处理
自测验证:
| 验证项 | 达标线 |
|---|---|
| Spec 驱动开发 | 产出 Spec 文档 + AI 生成的代码,代码一次通过 review 或仅需微调 |
| Prompt 质量 | 结构化 Prompt 输出的可用性明显高于随意版 |
| Spec 精度 | 精确版 Spec 的返工次数明显少于粗略版 |
阶段三:整合(持续)—— 让 AI 融入工具链
目标:AI 不只是聊天窗口,而是连接设计、数据、服务的入口
- MCP:让 AI 直连 Figma、数据库、内部 API,从”盲猜”变”有据可依”
- Skills / Hooks:把重复动作自动化——代码审查、安全检查、循环任务
- Rules 迭代:阶段一写了初版 Rules,现在根据 AI 犯过的错持续迭代,让 Rules 越来越精准
自测验证:
| 验证项 | 达标线 |
|---|---|
| Skills 使用 | 每个 Skill 产出可观察的结果(如 /simplify 后代码行数减少、/review 发现实际问题) |
| Rules 迭代 | 至少完成 2 次”犯错→补 Rule→验证生效”的闭环 |
| MCP 接入 | AI 借助 MCP 产出的结果准确性高于无 MCP 时 |
贯穿始终的关键认知
| 认知 | 说明 |
|---|---|
| 你决策,AI 执行 | 你负责思考和决策,AI 负责执行和扩展 |
| Spec > 逐行指挥 | 写清楚”要什么”,比指挥”怎么写”效率高得多 |
| Rules 是杠杆 | 一次写好,每次对话都生效,投入产出比最高 |
| 小步迭代 | 一次一个明确指令,逐步推进,每步确认 |
| 审查不可省略 | AI 生成的代码必须 review,你是最终责任人 |
五、踩过的坑和当前局限
踩过的坑
| 坑 | 教训 |
|---|---|
| 规则扁平堆砌 | AI 不知该看哪条,经常忽略重要约束 → 改为分层路由(归属判断) |
| 让 AI 直接写代码 | 写完发现方向偏了,返工更大 → 先走 proposal → design → tasks |
| 通用代码审查 | 帮助不大,开发同学不当回事 → 改为领域化审查 |
当前局限
| 局限 | 说明 |
|---|---|
| PRD 抓取依赖 Playwright | 钉钉文档结构变化时脚本需同步更新 |
| 规则镜像需人工维护 | .cursor/rules/ 和 .kiro/steering/ 目前是手动镜像,存在不一致风险 |
| AI 归属判断偶尔误判 | 复杂跨仓改动时,路由判断可能不够精准 |
| PRD 评审深度有限 | AI 能发现缺什么,但不能替代产品补全需求细节 |
六、三种模式的适用场景
没有银弹,三种模式各有适合的场景:
| 模式 | 适合什么 | 不适合什么 |
|---|---|---|
| 纯人肉 | 探索性原型、个人项目、极简改动 | 团队协作、多仓架构、长期维护 |
| Vibe Coding | 一次性脚本、学习练手、简单独立功能 | 多仓项目、有规范的团队、需要长期维护的代码 |
| 全流程工程化 | 团队项目、多仓架构、长期迭代、多人协作 | 一个人临时写个脚本(前期投入不值得) |
判断标准很简单:这段代码的生命周期有多长? 只需要跑一次,Vibe Coding 够了;需要活半年以上,全流程工程化才划算。
Vibe Coding 让 AI 替你打字,全流程工程化让 AI 替你思考——而且是有规矩地思考。